Overview
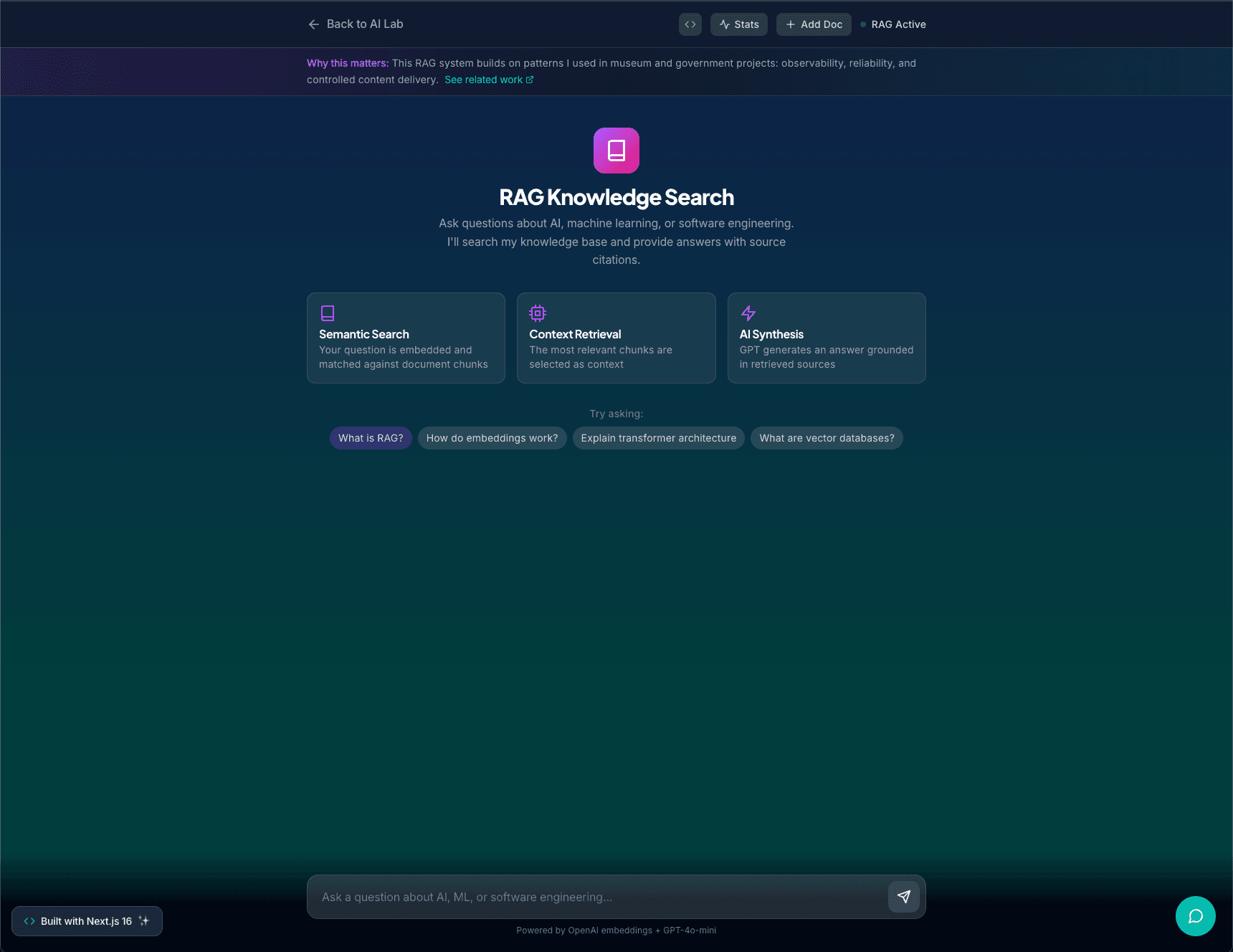
RAG Knowledge Search is an AI lab project that demonstrates applied AI engineering treated as a real product instead of a toy demo.
It lets users add their own documents into a knowledge base, ask natural language questions about that content, and get streaming answers from GPT-4o-mini that are grounded in retrieved text with source citations and match scores.
How It Works
Ingestion
A dedicated endpoint accepts a title and body text, validates input, chunks it into segments using a paragraph and sentence-aware strategy (capped at 800 characters per chunk), embeds those segments with OpenAI text-embedding-3-small, and stores the resulting vectors in Supabase pgvector.
Query and Retrieval
An endpoint embeds the user query, runs cosine similarity against all stored chunks, selects the top matches, and constructs an LLM prompt that includes the question and retrieved context. Answers stream token-by-token.
Chat Interface
A React page lets users ingest docs, see what they have added, and talk to the system through a streaming chat interface. The UI tracks conversation history and highlights which source chunks were used for each answer.
Technical Details
- OpenAI text-embedding-3-small for embeddings
- Supabase pgvector for persistent vector storage and similarity search
- Next.js 16 API routes with rate limiting and input validation
- Streaming responses via ReadableStream
- Per-IP document limits and character caps for abuse prevention
This project lives at /ai/rag on this site.